Советские шифры во второй мировой войне
Содержание:
- Внедрение шифрования
- Какие бывают виды шифрования?
- Статистические атаки насыщения
- Теперь пришло время одноключевых КА.
- Тайнопись древних цивилизаций
- Выбор кодировки при сохранении файла
- Общие сведения о кодировке текста
- Куда прятать подсказки для квеста?
- Способы обхода защиты документа
- Шифрование методом публичного ключа
- Частотный анализ
- Цифровая подпись
Внедрение шифрования
Давайте создадим функцию caesar_cipher(), которая принимает строку для шифрования/дешифрования, “набор символов”, показывающий, какие символы в строке должны быть зашифрованы (по умолчанию это будет строчный регистр),
ключ, а также булево значение, показывающее, была ли произведена расшифровка (шифрование) или нет.
Это очень мощная функция!
Вся операция смены была сведена к операции нарезки.
Кроме того, мы используем атрибут string.ascii_lowercase – это строка символов от “a” до “z”.
Еще одна важная особенность, которой мы здесь достигли, заключается в том, что одна и та же функция обеспечивает как шифрование, так и дешифрование; это можно сделать, изменив значение параметра ‘key’.
Операция вырезания вместе с этим новым ключом гарантирует, что набор символов был сдвинут влево – то, что мы делаем при расшифровке сдвинутого вправо шифротекста Цезаря.
Давайте проверим, работает ли это на предыдущем примере.
Мы зашифруем только заглавные буквы текста и передадим то же самое параметру “characters”.
Зашифруем текст: “HELLO WORLD! Welcome to the world of Cryptography!”.
Посмотрите, как часть “KHOOR ZRUOG” соответствует шифрованию “HELLO WORLD” с ключом 3 в нашем первом примере.
Также обратите внимание, что мы указываем набор символов для заглавных букв с помощью string.ascii_uppercase. Мы можем проверить, правильно ли работает расшифровка, используя тот же зашифрованный текст, который мы получили в нашем предыдущем результате
Мы можем проверить, правильно ли работает расшифровка, используя тот же зашифрованный текст, который мы получили в нашем предыдущем результате.
Если мы можем получить наш исходный текст, значит, наша функция работает идеально.
Обратите внимание, как мы установили параметр “decrypt” нашей функции в True. Поскольку мы восстановили наш оригинальный текст, это признак того, что наш алгоритм шифрования-дешифрования с использованием таблицы поиска работает отлично!
Поскольку мы восстановили наш оригинальный текст, это признак того, что наш алгоритм шифрования-дешифрования с использованием таблицы поиска работает отлично!
Теперь давайте посмотрим, можно ли расширить набор символов, включив в него не только строчные и прописные символы, но и цифры и знаки препинания.
Здесь мы включаем все символы, которые мы обсуждали до сих пор (включая символ пробела), в набор символов для кодирования.
В результате все (даже пробелы) в нашем обычном тексте было заменено другим символом!
Единственное отличие заключается в том, что обертывание происходит не по отдельности для строчных и прописных символов, а в целом для набора символов.
Это означает, что “Y” со смещением 3 не станет “B”, а будет закодирован как “1”.
Какие бывают виды шифрования?
С появлением ЭВМ стали создаваться и более сложные алгоритмы шифрования. Вместо деревянных табличек и механических машин человечество перешло на шифрование посредством двоичного кода.
Так появилось два основных типа шифрования: симметричное и ассиметричное.
При симметричном шифровании используется лишь один пароль или ключ. Работает он следующим образом.
В системе шифрования предусмотрен некий математический алгоритм. На его цифровой «вход» подается исходный пароль и текст отправления (фото, видео и т.д.). Далее информация шифруется и отправляется.
При получении срабатывает обратный алгоритм и проходит процедура дешифровки с использованием того самого пароля.
Проще говоря, если знать пароль, то безопасность симметричного шифрования резко стремится к нулю. Поэтому пароль должен быть максимально сложным и запутанным. Несмотря на определенные ограничения, симметричное шифрование очень распространено из-за простоты и быстродействия.
Второй вид шифрования — ассиметричное. В нем используются два пароля: открытый или публичный и закрытый или секретный. Открытый пароль получают все участники сети, а вот закрытый всегда остается на стороне либо сервера, либо другого приемника.
Суть в том, что при ассиметричном шифровании расшифровать сообщение можно лишь с помощью двух ключей. Именно на этом принципе основан популярный протокол SSL, который мы часто встречаем в браузере.
Сталкиваться с таким шифрованием вы могли, когда получали сообщение при открытии страницы «Небезопасное соединение». Означает это лишь одно: закрытый ключ уже мог быть вскрыт и известен хакерам. А значит вся введенная вами информация, по сути, не шифруется.
Преимущество ассиметричного шифрования в том, что один из ключей всегда остается на устройстве и не передается. Но оно считается «более тяжелым» и требует больше ресурсов компьютера.
Статистические атаки насыщения
Не только простейшие шифры подвержены статистическим методам криптоанализа. Например, статистические атаки насыщения направлены на блочные шифры, которые в настоящее время широко использутся в криптографических протоколах. Проиллюстрировать принцип таких атак удобно на блочном шифре PRESENT.
PRESENT
PRESENT — блочный шифр на основе SP-сети с размером блока 64 бита, длиной ключа 80 или 128 бит и количеством раундов 32. Каждый раунд состоит в операции XOR с текущим ключом, далее происходит рассеивание — пропускание через S-блоки, а затем полученные блоки перемешиваются.
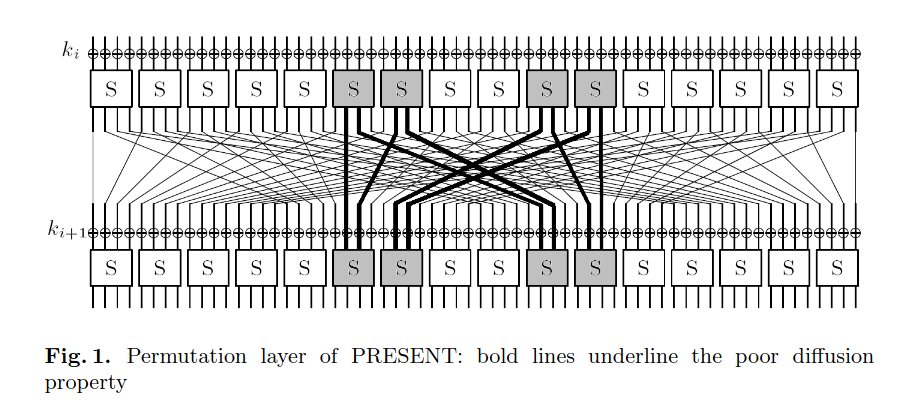
Предложенная атака основывается на уязвимости шифра на этапе перемешивания. Как показано на изображении, из входных битов 5, 6, 9 и 10 s-блоков половина соединений идет в те же самые блоки. И это только один пример подобной слабости. Значит, фиксируя 16 битов на входе 5, 6, 9 и 10 s-блоков, можно определить 8 входных битов для этих блоков на следующем раунде.
Предполагая ключ на данном шаге, криптоаналитик может по выбранном распределению выбранных 8 битов на входе определить распределение тех же 8 битов на выходе. Проделав эту процедуру для каждого ключа, можно понять все возможные распределения выбранных 8 выходных битов 5, 6, 9 и 10 s-блоков на каждом слое, применяя алгоритм итеративно.
Когда криптоаналитик знает для каждого ключа, как распределены выбранные 8 битов на каждом слое, он может сравнить полученные распределения с теми, которые получаются в реальной системе. Для этого нужен доступ к алгоритму шифрования и большое количество текстов для шифрования. Из всех возможных ключей выбирается тот, который минимизирует расстояние между теоретическим и экспериментальным распределениями.
Теперь пришло время одноключевых КА.
DES
- ECB (англ. electronic code book) — режим «электронной кодовой книги» (простая замена);
- CBC (англ. cipher block chaining) — режим сцепления блоков;
- CFB (англ. cipher feed back) — режим обратной связи по шифротексту;
- OFB (англ. output feed back) — режим обратной связи по выходу.
- Прямым развитием DES в настоящее время является алгоритм Triple DES (3DES). В 3DES шифрование/расшифровка выполняются путём троекратного выполнения алгоритма DES.
RC4
- высокая скорость работы;
- переменный размер ключа.
- используются не случайные или связанные ключи;
- один ключевой поток используется дважды.
Illivion
Blowfish
- скорость (шифрование на 32-битных процессорах происходит за 26 тактов);
- простота (за счёт использования простых операций, уменьшающих вероятность ошибки реализации алгоритма);
- компактность (возможность работать в менее, чем 5 Кбайт памяти);
- настраиваемая безопасность (изменяемая длина ключа).
Twofish
- 128-битный блочный симметричный шифр
- Длина ключей 128, 192 и 256 бит
- Отсутствие слабых ключей
- Эффективная программная (в первую очередь на 32-битных процессорах) и аппаратная реализация
- Гибкость (возможность использования дополнительных длин ключа, использование в поточном шифровании, хэш-функциях и т. д.).
- Простота алгоритма — для возможности его эффективного анализа.
Skipjack
Принимая во внимание, что стоимость вычислительных мощностей уменьшается вдвое каждые 18 месяцев, лишь через 36 лет стоимость взлома Skipjack полным перебором сравняется со стоимостью взлома DES сегодня.
Риск взлома шифра с помощью более быстрых способов, включая дифференциальный криптоанализ, незначителен. Алгоритм не имеет слабых ключей и свойства комплементарности.
Устойчивость Skipjack к криптоанализу не зависит от секретности самого алгоритма.
Mars
- простейшие операции (сложение, вычитание, исключающее или)
- подстановки с использованием таблицы замен
- фиксированный циклический сдвиг
- зависимый от данных циклический сдвиг
- умножение по модулю 232
- ключевое забеливание
Idea
- сложение по модулю
- умножение по модулю
- побитовое исключающее ИЛИ (XOR).
- никакие две из них не удовлетворяют дистрибутивному закону
- никакие две из них не удовлетворяют ассоциативному закону
Тайнопись древних цивилизаций
За наукообразным словом «криптография» (с древнегреческого буквально − «тайнопись») скрывается древнее желание человека спрятать важную информацию от посторонних глаз. Можно сказать, что сама письменность в самом начале уже была криптографической системой, так как принадлежала узкому кругу людей, и с помощью нее они могли обмениваться знаниями, недоступными неграмотным. С распространением письма возникла потребность в более сложных системах шифрования. Со времен древних цивилизаций криптография верно служила военным, чиновникам, купцам и хранителям религиозных знаний.
Самым древним свидетельством применения шифра (около 4000 до н.э.) ученые считают древнеегипетский папирус с перечислением монументов времен фараона Аменемхета II. Безымянный автор видоизменил известные иероглифы, но, скорее всего, не для сокрытия информации, а для более сильного воздействия на читателя.
Фрагмент хирургического папируса, одного из наиболее важных медицинских текстов Древнего Египта
Еще один известный шифр – древнесемитский атбаш, приблизительно 600 г. до н.э. Здесь информацию запутывали самым простым способом − с помощью подмены букв алфавита. Криптограммы на атбаше встречаются в Библии.
А в Древней Спарте пользовались скиталой – шифром из цилиндра и обвивающей его полоски пергамента. Текст писали в строку на пергаменте. После разматывания ленты текст превращался в шифр, прочитать который было возможно, только имея цилиндр такого же диаметра. Можно сказать, что спартанская скитала стала одним из первых криптографических устройств.
В IV столетии до н.э. автор военных трактатов Эней Тактик придумал шифровальный диск, названный впоследствии его именем. Для записи сообщения в отверстия диска с подписанными рядом с ними буквами последовательно продевалась нить. Чтобы прочитать текст, нужно было всего лишь вытягивать нить в обратной последовательности. Это и составляло основной минус устройства – при наличии времени шифр мог быть разгадан любым грамотным человеком. Зато, чтобы быстро «стереть» информацию с диска Энея, нужно было всего лишь вытянуть нить или разбить устройство.
Шифр Цезаря со сдвигом на 3: A заменяется на D, B заменяется на E и так далее. Z заменяется на C
Одним из первых документально зафиксированных шифров является шифр Цезаря (около 100 г. до н.э.). Его принцип был очень прост: каждая буква исходного текста заменялась на другую, отстоящую от нее по алфавиту на определенное число позиций. Зная это число, можно был разгадать шифр и узнать, какие тайны Цезарь передавал своим генералам.
Шифрованием пользовались многие древние народы, но особенного успеха в криптографии уже в нашу эру достигли арабские ученые. Высокий уровень развития математики и лингвистики позволил арабам не только создавать свои шифры, но и заниматься расшифровкой чужих. Это привело к появлению первых научных работ по криптоанализу – дешифровке сообщений без знания ключа. Эпоха так называемой наивной криптографии, когда шифры были больше похожи на загадки, подошла к концу.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Нажмите кнопку Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Общие сведения о кодировке текста
Информация, которая выводится на экран в виде текста, на самом деле хранится в текстовом файле в виде числовых значений. Компьютер преобразует эти значения в отображаемые знаки, используя кодировку.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Куда прятать подсказки для квеста?
Места для прятания подсказок – это какие-либо предметы, в которых (под которыми, на которых или возле которых) можно спрятать листочки с подсказками (подушка, телевизор, кастрюля, пылесос…). То есть это такие ключевые слова или фразы, которые нужно разгадать в текущем задании квеста, чтобы перейти к следующему.
Предметы нужно подбирать так, чтобы они не были слишком близко к друг другу и уж тем более не находились один в другом. Это необходимо для минимизации риска того, что при поиске оной подсказки будет найдена другая.
Если есть необходимость или желание, то можно сузить радиус поиска, уточнив какой именно предмет имеется ввиду. Например, подушек в квартире может быть много и бумажка с подсказкой может быть в любой из них. Во избежание бессмысленного перетряхивания пустых подушек можно, вместо просто «подушка» ввести «твоя подушка», «подушка на твоей кровати», «зелёная подушка» и т.п.
Увеличение количества букв в расшифровываемом тексте чаще всего ведёт к увеличению сложности задания. Поэтому для усложнения задания, помимо ползунка сложности, можно добавлять к слову, обозначающему предмет, дополнительные слова. Например, вместо «стол» можно ввести «ищи под столом», «загляни под стол», «следующая подсказка под столом» и т.п. Однако учтите, что задания имеют ограничения по длине вводимого текста.
Ключевыми словом или фразой для поиска очередной подсказки может быть не только название самого предмета, но и какое-то его свойство или признак. Например, если листок с подсказкой спрятать на неприбранном, заваленном чем-то столе, то ключевым словом для поиска этой подсказки может быть «бардак». Разгадавший это слово сам должен догадаться в каком бардаке нужно искать следующую подсказку. Также подсказку можно спрятать в книгу с рассказами, а в качестве места для прятания указать название соответствующего рассказа или имя его главного героя.
Придуманные вами предметы (места) вам нужно впечатать в соответствующие поля при создании подсказок.
Обратите внимание, что если вы делаете квест с распечаткой, то при создании очередной подсказки вы вводите наименование места, где будет спрятана следующая подсказка. Так, при создании 1-ой подсказки указывается место для прятания 2-ой подсказки, при создании 2-ой подсказки указывается место, где будет спрятана 3-я подсказка и так далее
При создании последней подсказки нужно ввести место, где будет спрятан подарок. Первая подсказка не прячется.
Если вы делаете квест без распечатки (с вариантом, где нужно находить листочки с паролями для перехода к следующим заданиям), то при создании очередной подсказки вы вводите наименование места, в котором будет спрятан указанный в этой же подсказке пароль, дающий доступ к следующему заданию.
Способы обхода защиты документа
С защитой разобрались самое время рассмотреть способы ее обхода.
Сразу скажем, что если документ требует при открытии пароль, то обойти такую защиту не получиться. Только подбор пароля с помощью специализированных программ. Это займет время в зависимости от сложности пароля.
Рассмотрим способ обхода защиты от изменения документа и от копирования. Есть одна поправка. Это сработает с документами сделанным в Microsoft Word 2007 и старше. То есть для документов с расширением docx
Сделать нужно следующее:
- Меняете расширение документа на zip
- Открываете полученный архив и вытаскиваете из него файл settings.xml
- Открываете на редактирование settings.xml и убираете из него информацию Заключение
В статье рассмотрели различные варианты защиты документа: на открытие, на редактирование и на копирование. Самая серьезная защита это шифрование документа паролем на открытие. Тут уже ничем не откроешь, только вспоминать или использовать специальные программы. По поводу других защит, есть вариант с переименованием в архив. Он отлично работает для документов Microsoft Word 2007 и выше. Для более стареньких версий это не вариант. Попробовал эти документы открыть для редактирования в OpenOffice. Ничего не получается. Единственное что можно это скопировать содержимое документа защищенного от копирования и вставить в другой документ для редактирования.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Шифрование методом публичного ключа
Самый популярный из алгоритмов шифрования, который используется повсеместно в технике и компьютерных системах. Его суть заключается, как правило, в наличии двух ключей, один из которых передается публично, а второй является секретным (приватным). Открытый ключ используется для шифровки сообщения, а секретный — для дешифровки.
В роли открытого ключа чаще всего выступает очень большое число, у которого существует только два делителя, не считая единицы и самого числа. Вместе эти два делителя образуют секретный ключ.
Рассмотрим простой пример. Пусть публичным ключом будет 905. Его делителями являются числа 1, 5, 181 и 905. Тогда секретным ключом будет, например, число 5*181. Вы скажете слишком просто? А что если в роли публичного числа будет число с 60 знаками? Математически сложно вычислить делители большого числа.
В качестве более живого примера представьте, что вы снимаете деньги в банкомате. При считывании карточки личные данные зашифровываются определенным открытым ключом, а на стороне банка происходит расшифровка информации секретным ключом. И этот открытый ключ можно менять для каждой операции. А способов быстро найти делители ключа при его перехвате — нет.
Частотный анализ
Простые шифры
Частотный анализ использует гипотезу о том, что символы или последовательности символов в тексте имеют некоторое вероятностное распределение, которое сохраняется при шифровании и дешифровании.
Этот метод один из самых простых и позволяет атаковать шифры простой замены, в которых символы в сообщении заменяются на другие согласно некоторому простому правилу соответствия.
Однако такой метод совершенно не работает, например, на шифрах перестановки. В них буквы или последовательности в сообщении просто меняются местами, но их количество всегда остается постоянным, как в анаграммах, поэтому ломаются все методы, основанные на вычислении частот появления символов.
Для полиалфавитных шифров — шифров, в которых циклически применяются простые шифры замены — подсчет символов так же не будет эффективен, поскольку для кодировки каждого символа используется разный алфавит. Число алфавитов и их распределение так же неизвестно.
Шифр Виженера
Один из наиболее известных примеров полиалфавитных шифров — шифр Виженера. Он довольно прост в понимании и построении, однако после его создания еще 300 лет не находилось способа взлома этого шифра.
Пусть исходный текст это: МИНДАЛЬВАНГОГ
-
Составляется таблица шифров Цезаря по числу букв в используемом алфавите. Так, в русском алфавите 33 буквы. Значит, таблица Виженера (квадрат Виженера) будет размером 33х33, каждая i-ая строчка в ней будет представлять собой алфавит, смещенный на i символов.
-
Выбирается ключевое слово. Например, МАСЛО. Символы в ключевом слове повторяются, пока длина не достигнет длины шифруемого текста: МАСЛОМАСЛОМАС.
-
Символы зашифрованного текста определяются по квадрату Виженера: столбец соответствует символу в исходном тексте, а строка — символу в ключе. Зашифрованное сообщение: ЩЙЯРПШЭФМЬРПХ.

Этот шифр действительно труднее взломать, однако выделяющиеся особенности у него все же есть. На выходе все же не получается добиться равномерного распределения символов (чего хотелось бы в идеале), а значит потенциальный злоумышленник может найти взаимосвязь между зашифрованным сообщением и ключом. Главная проблема в шифре Виженера — это повторение ключа.
Взлом этого шифра разбивается на два этапа:
-
Поиск длины ключа. Постепенно берутся различные образцы из текста: сначала сам текст, потом текст из каждой второй буквы, потом из каждой третьей и так далее. В некоторый момент можно будет отвергнуть гипотезу о равномерном распределении букв в таком тексте — тогда длина ключа считается найденной.
-
Взлом нескольких шифров Цезаря, которые уже легко взламываются.
Поиск длины ключа — самая нетривиальная здесь часть. Введем индекс совпадений сообщения m:
где n — количество символов в алфавите и
p_i — частота появления i-го символа в сообщении. Эмпирически были найдены индексы совпадений для текстов на разных языков. Оказывается, что индекс совпадений для абсолютно случайного текста гораздо ниже, чем для осмысленного текста. С помощью этой эвристики и находится длина ключа.
Другой вариант — применить критерий хи-квадрат для проверки гипотезы о распределении букв в сообщении. Тексты, получаемые выкидыванием некоторых символов, все равно остаются выборкой из соответствующего распределения. Тогда в критерии хи-квадрат вероятности появления символов можно выбрать используя частотные таблицы языка.
Цифровая подпись
ГОСТ 34.10-2018 описывает алгоритмы формирования и проверки электронной цифровой подписи с помощью операций в группе точек эллиптической кривой и функции хеширования. Длины секретного ключа 256 бит и 512 бит.
У пользователя есть сообщение, ключ подписи и ключ для проверки подписи. Ключ проверки подписи является открытым, для того, чтобы любой получатель смог расшифровать и убедиться в достоверности подписи. То есть если получателю удается расшифровать сообщение с помощью открытого ключа проверки подписи, принадлежащего определенному отправителю, то он может быть уверен, что сообщение подписывалось ключом подписи именно этого отправителя.
В алгоритмах формирования и проверки электронной цифровой подписи важным шагом является вычисление точки на эллиптической кривой, поэтому, прежде чем переходить к самим алгоритмам, приведем используемые понятия.
Эллиптической кривой над конечным простым полем , где , называется множество точек , , удовлетворяющих уравнению (в форме Вейерштрасса) , где , .
Суммой точек , эллиптической кривой называется точка , координаты которой определяются, как , , где .
Точка эллиптической кривой , может быть определена через сумму точек .
Разбор теории, необходимой для криптографии на эллиптических кривых, можно найти тут.
Алгоритмы формирования и проверки электронной цифровой подписи.
Подпись создается по следующему алгоритму.
входные данные: сообщение и закрытый ключ подписи .
— к сообщению применяется хеш-функция(Стрибог) и вычисляется хеш-код сообщения , отметим, что хеш-код — это строка бит.
— определяется число , где — целое число, которое соответствует двоичному представлению хеш-кода . Причем если , то принимается за 1. — это порядок порядок циклической подгруппы группы точек эллиптической кривой, который является одним из параметров цифровой подписи. Также среди параметров есть — это базовая точка подгруппы.
— на основе случайно сгенерированного целого числа , это число называют секретным ключом. Затем вычисляется точка на эллиптической кривой . Точка имеет координаты .
— из координаты точки на эллиптической кривой и преобразования хеша вычисляется электронная подпись , где . Если либо , либо равняется 0, то нужно вернуться к предыдущему шагу.
выходные данные: цифровая подпись которую добавляют к сообщению.
Теперь перейдем к алгоритму проверки подписи.
входные данные: сообщение c цифровой подписью и ключ проверки подписи
— полученная цифровая подпись проходит первичную проверку, если проверка не пройдена, то есть не выполнены неравенства , то подпись неверна.
— вычисляется хеш-код сообщения , опять же с помощью алгоритма Стрибог.
— определяется число , где целое число, которое соответсвует двоичному представлению хеш-кода . Причем если , то принимается за 1. Затем определяется .
— вычисляется точка эллиптической кривой , из которой получается .
— если , то подпись верна
выходные данные: подпись вена/неверна
